Intro
The primary function of a captcha is to prevent an automated software simulating human activities like registering forms, view important information etc. They are used as a precaution to prevent automated software of copying content, or protecting a system from automated requests.
They work pretty well, but implementation errors are very common.
Captchas is a thing I have studied a lot and I enjoy breaking. There are many weaknesses one might exploit, implementation errors where it’s enough just to not sent the captcha variable, or neural networks that you can train to solve a specific implementation. Even plain OCR software work if the captcha is clean enough. gocr is a linux command line tool I often use (in my perfectly legal white-hat activities 😀 )
If you have a website with enough traffic, you can get real visitors solving your captchas without them realizing it. You just copy the image and ask them to write the captcha code, them thinking its a real captcha will copy it correctly. That was the most genius method I have thought and have won me lots of bets.
Today’s solution though is 100% code.
forth.gr uses a captcha to stop automatic whois requests at: https://grweb.ics.forth.gr/public/whois.jsp?lang=en. Its not something that I use every day and don’t care must to automate, I just thought it is was fun to try.
I should mention that this tool, has unique information not appearing in standard international whois services. for example see http://whois.domaintools.com/in.gr and then search in the above website. Results are very different. This is pretty much the case with all country-level TLD.
Why break the .gr registry captcha
- Because I can 🙂
- Because I was stranded in Troodos hotel in a snowy day (HOW COOL IS THAT ??), in a perfect setting, with lots of hours to kill, and an Internet connection + my laptop.
Yes I am a geek. And I love it 🙂
How
So, this is the forth.gr whois captha:

It is not clear enough to be solved only with an OCR software, but there are lots of thins wrong with it.
- There are only 2 colors in the image.
- The captcha is always 6 digits.
- The char set is limited (only digits, no letters)
- The noise part of the image is basically a grid.
I though, this should be simple enough to solve. I started to think how I can approach this. At this point I should note that I am extreamly lazy and my image processing abilities are minimal.
The goal is to eliminate the grid. The method I thought first was that:
- I loop through all pixels in the image.
- When I found a non black, non transparent pixel I do the following (red line):
- I look 5 pixels down.
- If I don’t find a black pixel, I paint that pixel “transparent”.
- If I find a black pixel, I paint the initial pixel black too.
Red part here will be transformed to transparent because there are no black pixels below.
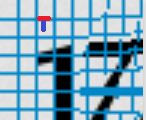
Red part below will be transformed to black because pixels below are black:

The code for that is just 2 loops, one inside the other, like you loop a 2 dimentional array and a third loop that scans the pixels below.
That covers the horizontal lines and gives us something like this:

After that I go through a second pass.
- If pixel is not black AND
- If a pixel on the left OR a pixel on the right is black, I mark this pixel too black.
That gives us that:

At this point I thought, this looks clear enough, lets try OCR. I tried gocr, with no success. Then I tried javaocr package, but still no luck.
Then I found tess4j, that uses Google Tesseract OCR. There is a cool feature where you can define the working characters you are interested in. That helps the OCR software a lot and increases the ods a lot.
After that cracking worked in about 40% of the cases, so I didn’t bother clearing the image further.
If you ever try something like this, keep in mind imagemagick, a commandline tool that makes images transformation. We could smooth the image a little to make the percentages better, but 40% us already high enough.
All code is published at my github page: https://github.com/nikos-glikis/ForthPwn
Wisdom
I don’t consider this a great hack. I only want to demonstrate a simple solution to what it seems a complicated problem from a programming point of view.
Wisdom for hackers:
The lesson here is: Always keep in mind that each case is unique. Unique case means that you can approach it differently, more optimized, more targeted. For example here OCR in general is not enough. All OCR solutions assume, clean text and try to match every character in the English alphabet.
Our situation is a lot different: We have only digits and we know there exact count: 6. Matching a character with one out of 10 symbols is a lot more easier that matching it in 62 (Upper lower special characters etc).
Problems analyzed by researches assume optimal conditions and specific environment. When they say something is impossible, they mean something is impossible within these optimal parameters and assumptions. Always look for the differences in your specific situation and envoronment and try to understand how that changes your situation, how the different parameters can be exploited, what advantages you gain from those.
That’s how most hacks are made. Solutions are usually a lot more simpler than one thinks.
Wisdom for developers:
Captchas can be hacked. Make them complicated. That.
Hacker definition
As my grandpa says (:D) :
“O hacker gie mou, enen tzinos pou trexei to exploit, en tzinos pou shizeei o nous tou”
Thanks for visiting !